Batch Normalization解析
论文链接 : https://arxiv.org/abs/1502.03167
介绍
Batch Normalization 是批归一化,用来解决神经网络中协方差偏移问题,就是每一层的分布很混乱,除非从第一层开始每一层的输入的分布都很有效,否则就得不到好的效果。如下图所示。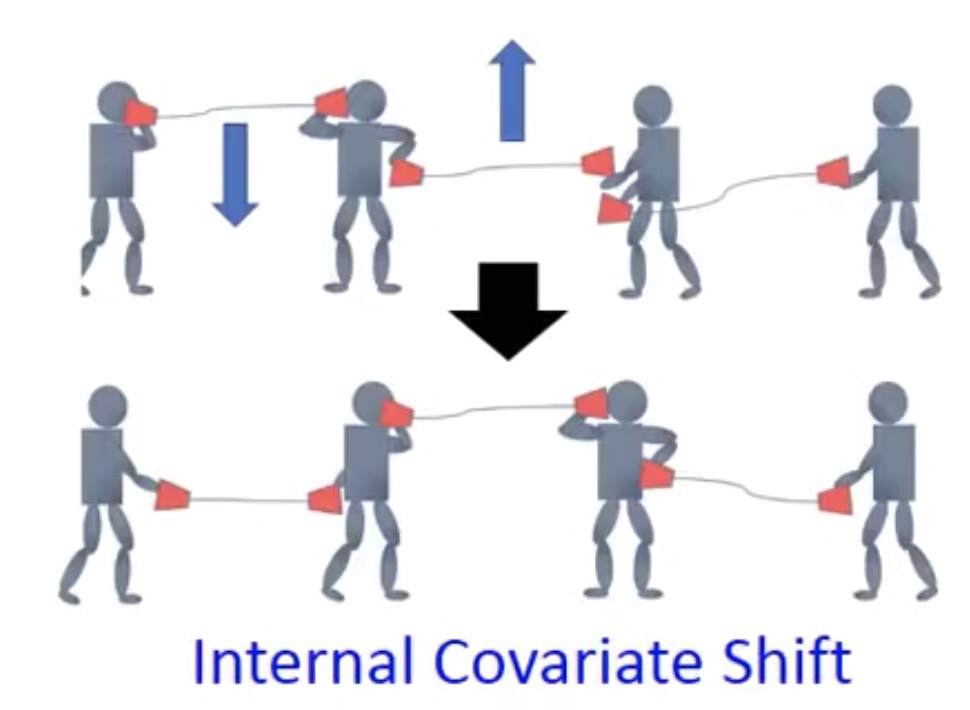
所以,为了解决这个问题,我们引入了Batch Normalization.
介绍一下在机器学习中,是如何做feature scaling,因为输入的不同变量分布不同,比如说x1可能是代表房子的房间数量,x2代表房子的大小多少平方,那么x2和x1很显然不属于统一量纲,所以要做归一化,如下图所示。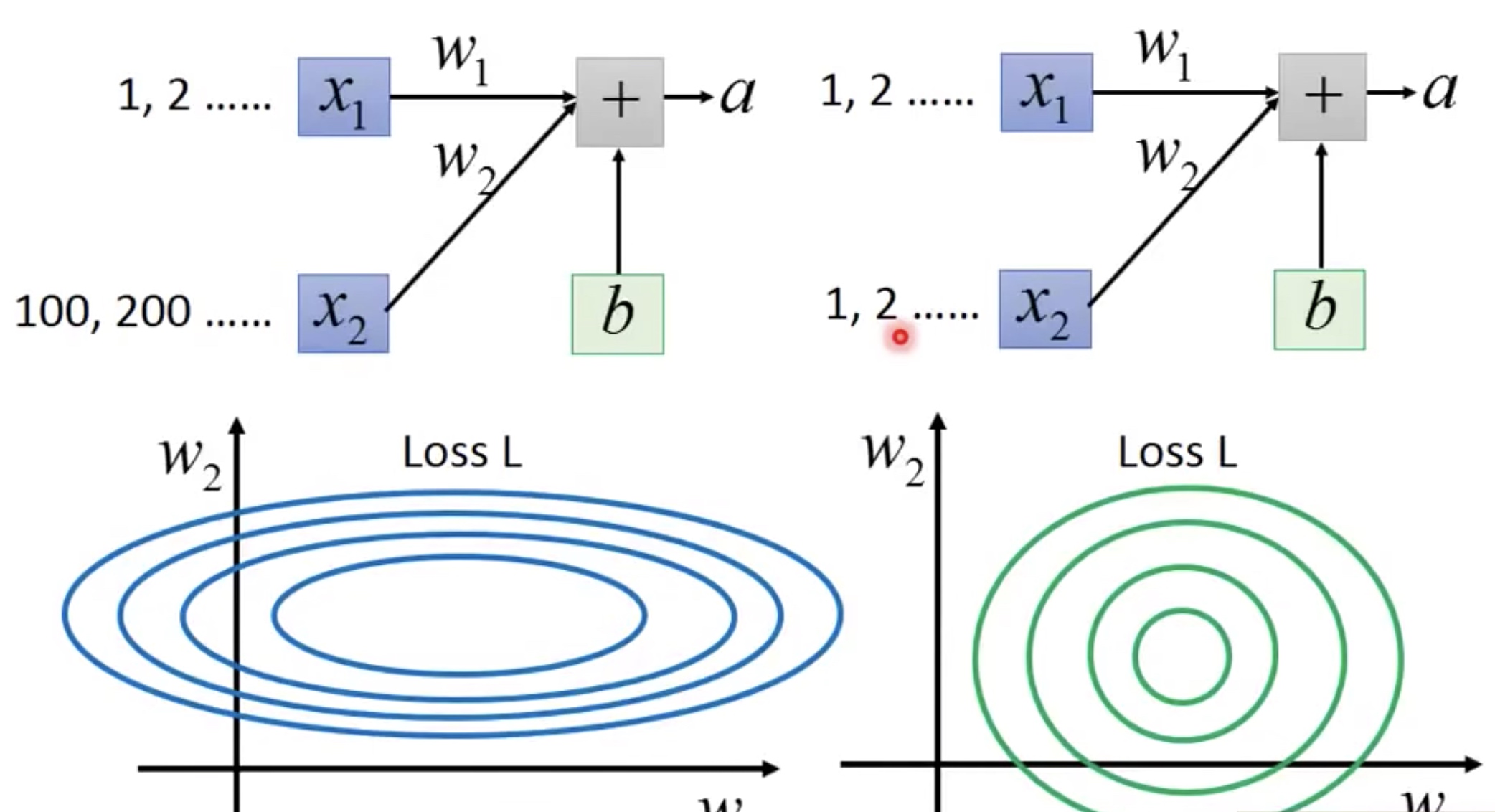
原理
顾名思义,Batch Normalization是对一个batch的数据做处理,
- 求均值
- 除以标准差
- 仿射变换(可选)(有时候需要把均值和方差调整到某些范围时可以加上)
- 然后将Batch Normalization的结果送给激活函数层,才能比较好的发挥激活函数的作用。
举个栗子,比如像Sigmoid函数,如果不做Batch Normalization,可能会导致输入分布在两边(就是不集中在[-1,1] ),梯度就很小,链式相乘之后就会接近于0,做了Batch Normalization,把输入集中在0附近,使得激活函数更好地发挥作用。
pytorch实现
pytorch api
1 | torch.nn.BatchNorm1d(num_features, |
affine是仿射,track_running_stats是保留在训练时候的数据方差和均值,从而运用到测试中,因为在测试中是不方便计算方差和均值的,当batch_size很小的时候,应该设置为False。
- 训练模式下 track_running_stats=True, 这是常用的training时期待的行为,running_mean 和running_var会跟踪不同batch数据的mean和variance,但是仍然是用每个batch的mean和variance做normalization。
- 训练模式下, track_running_stats=False, 这时候running_mean 和running_var不跟踪跨batch数据的statistics了,但仍然用每个batch的mean和variance做normalization。
- 测试模式下, track_running_stats=True, 这是我们期待的test时候的行为,即使用training阶段估计的running_mean 和running_var。
- 测试模式下, track_running_stats=False,仍然用每个batch的mean和variance做normalization。
要注意在训练的时候选择model.train()模式
在测试的时候选择model.eval()模式,这样Batch Normalization中的参数才会固定。
知乎上有个BN为什么能够解决梯度消失和爆炸问题的回答写的很好:
https://www.zhihu.com/question/38102762/answer/391649040

Author: leexuan
Link: http://xuanli19.github.io/2019/08/08/Batch-Normalization/
License: 知识共享署名-非商业性使用 4.0 国际许可协议
