《You Only Look Once》YOLOv1论文笔记
YOLO v1
论文:《You Only Look Once: Unified, Real-Time Object Detection》
论文地址:http://www.arxiv.org/pdf/1506.02640.pdf
简介
作者提出把目标检测任务当做回归任务来做,用一个神经网络来完成bbox(bounding box)以及class probabilities(类别概率)的回归,因为网络是单个完整的,不同于Faster R-CNN是分为RPN(Region Proposal Network,区域建议网络,用来生成一些proposal,输给后续的回归网络)和回归网络。所以YOLO网络是可以端到端的训练。
网络结构

YOLO系统流程
- 输入图片img
- resize到指定尺寸
- 通过预先设计好的多层CNN(一般包括特征抽取的VGG,以及回归层等)
- 根据回归层输出的坐标和置信度confidence来对proposal进行筛选
主要的网络结构如图
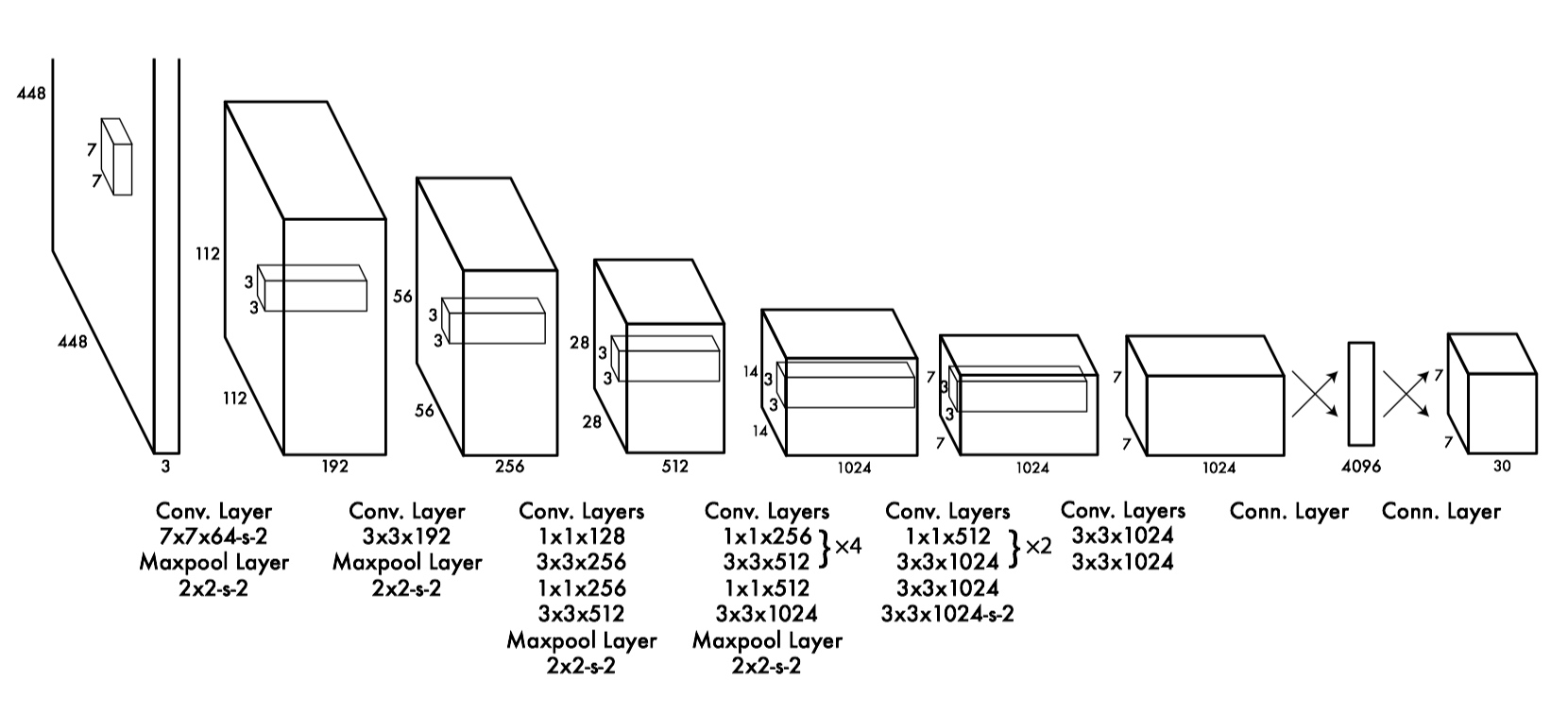
如上图所示,输入一个图片,resize到448*448的,经过N多卷积网络层得到7*7*30的feature map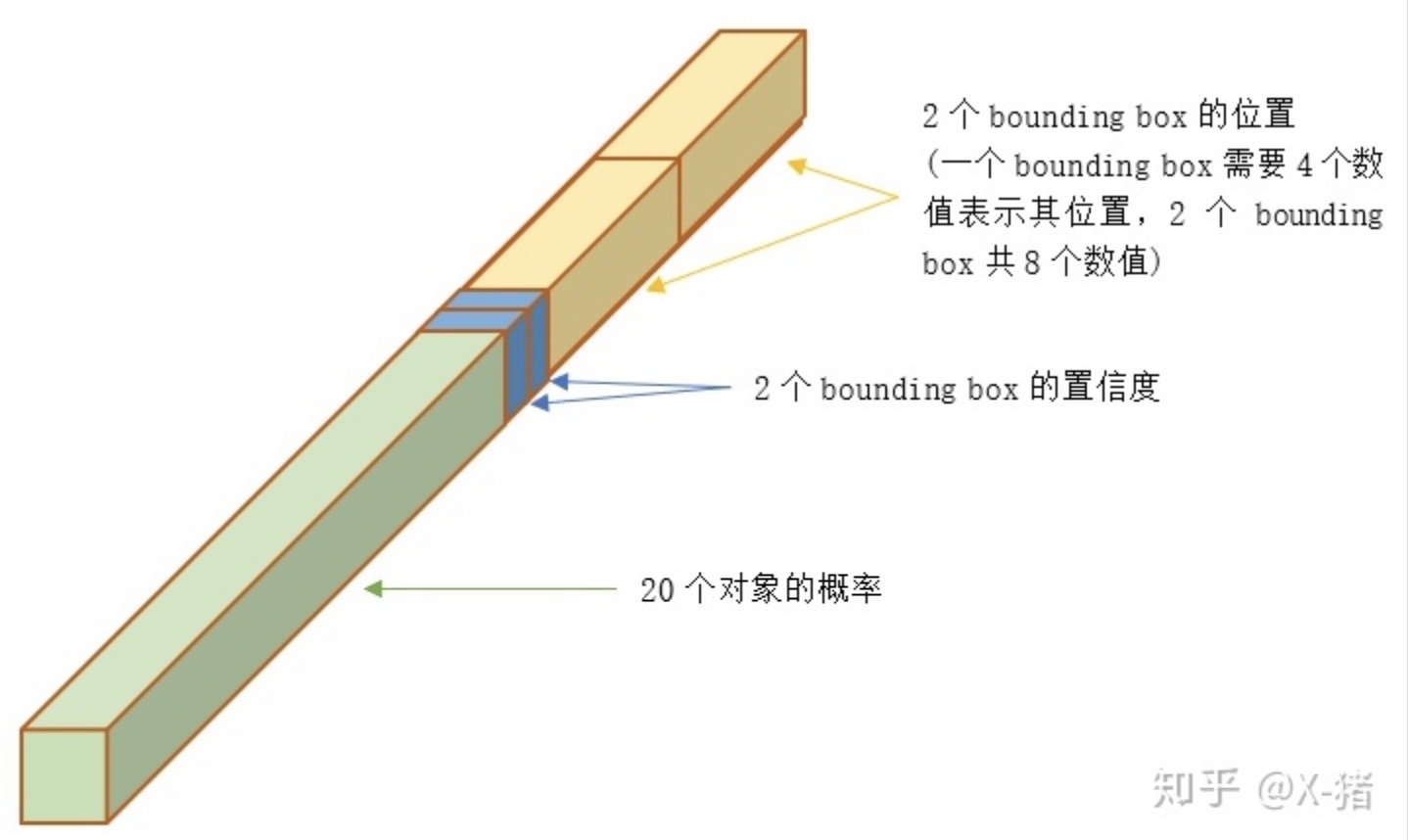
图片源于知乎用户这个维度30的意义如下图所示,包括confidence*2,(x1,y1)(x2,y2)四个坐标*2,20个类别概率(哪个概率大就是哪一类,用softmax实现),每一个30维的vector代表一个7*7的feature map 的每一个cell里面的信息。
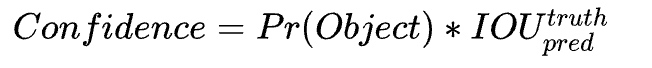
置信度在训练时计算如上图所示,Pr(object)就是选择一个cell中与训练样本ground truth的IOU大的那个proposal为1,另一个为0,所以这个置信度即为IOU或0。
Loss Function

如图所示,损失函数包括三部分:坐标回归损失、分类损失和置信度损失。坐标回归损失只是针对那些被认定为包含object的proposal才进行计算,对于没有检测到object的proposal不需要坐标回归的loss,分类损失也是检测到object的proposal要计算。还有一个置信度误差,不管有没有检测到object都要去计算。
Problem
- 每个vector的30维中只有一个20维的class probability ,但是有两个5维(4个坐标+1个置信度)向量,这代表了实际上7*7的feature map中的每一个单元都只能预测一个object,那么对于每个object为什么要使用两个回归向量呢?是为了精确地解决回归问题,最后这两个回归出来的proposal最多保留IOU大的那一个。
Author: leexuan
Link: http://xuanli19.github.io/2019/08/01/YOLOv1/
License: 知识共享署名-非商业性使用 4.0 国际许可协议
